
Starting a research project means managing the project data somehow. Sometimes, the workflow setup can be branched-off existing project within an established paradigm; sometimes not - when parts of the processing tools and/or logic is in development as well. Then one needs to arrange a new design, and a great number of available solutions hints that a well-established general one is not yet known.
While struggling with a main theme of my current occupation (that involves implementing a thermal transport method in one ab-initio molecular-dynamics capable program and comparing the results with obtained by another, not less sophisticated reference code), I've tried a bunch of workflow approaches, starting with initially proposed AiiDA - a production-ready mature package for high-throughput calculations. Just what doctor prescribed, unless one has to occasionally change the workflow design and the wrapped calculation executables like several times a day. The mandatory provenance model together with many abstraction layers in the core package would hinder the development a great deal.
During the search for more manageable approach I've even used my own homebrew stuff made with Lisp^{TM} (with a trick worth mentioning in another short post). But many of those are not convenient in the long run in a flexible and changing setup.
So I ended up using Common Workflow Language together with relational
database as a data storage. The database as minimalistic as SQLite is
an efficient substitute to spreadsheets and (OMG) raw .csv data files.
Moreover, with automatic schema generation of some kind it can be later
opted-out for a more suitable production solution such as Postgres.
As for the CWL, its reference local cwltool engine has also replacement
analogs that run on remote clusters. So, in principle, going from
prototype to a widely scaled production pipeline should be straightforward.
Details on sampling such a prototype (using exclusively FOSS) follow.
§ Designing SQL Schema
For that purpose UML editors with DB schema export should work fine.
In fact even open source Dia editor works fine, when paired with
parsediasql exporting script.
The inspiration and usage pattern can be found in this original post.
But while dia is most probably present in your distro repository,
parsediasql took me some time to locate. Turned out in Ubuntu
the corresponding package is now called libparse-dia-sql-perl.
The info on the script can be found on its CPAN page; with examples
under t/ in the source (look for the references of perldoc Parse::Dia::SQL).
I also like this repo with actual e-commerce database schema design in Dia.
This is how a diagram for my Thermal Transport project looks like:
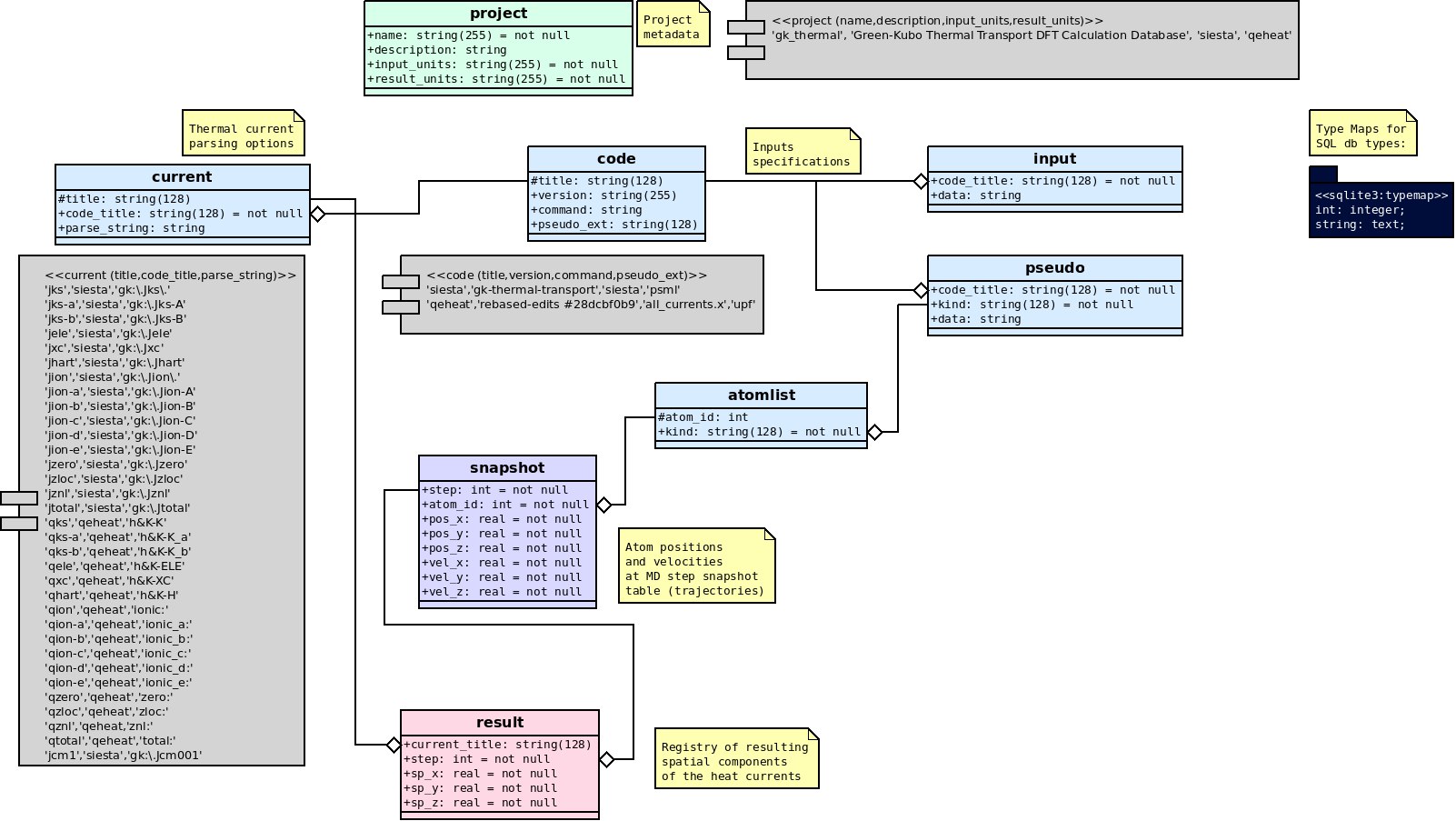
UML diagram "Classes" form tables, of which the parsing options, metadata and inputs (green and blue) are pre-populated with default data from "Components" (grey) and are meant to be edited at the beginning of work on each project. The general idea is that each project deals with a particular physical system compound and certain version of DFT calculator executables. In the work process the snapshot table is populated with atom positions along the Molecular Dynamics trajectory, and result then stores resulting thermal flux components at each of those steps.
Such design also implies a couple of important properties:
All the input data necessary to perform any of the calculations is stored in the database too, and the workflow mechanism only refers to it as a source of all input data. That secures data organization and provenance (provided the metadata is informative enough to e.g. recreate the executable toolchain).
Different "Typemaps" allow the export of schemas for various database flavors, not only SQLite (that is fine for prototyping and small projects, but not as good as e.g. Postgres for serious production runs). Likewise, the Common Workflow Language used to perform the workflow is positioned as an open standard having engines apart from a local-only
cwltool. Some of those engines are aware of job schedulers and cluster environments. That effectively means that once written and tested locally, such pipeline design should be straightforward to scale on a production research setup.
§ CWL Usage
Provided the project data storage is designed, I then write CWL scenario wrappers.
My repository for the Green-Kubo project contains ~30 of the .cwl scripts for each
elementary action: loading inputs, launching DFT exec, parsing results. Once I used to
write heavy monolithic workflows, but now I do think that less is more.
CWL in my point of view is just a way to write scripts that are both very formal about their input-output parameters and straightforwardly composable - as you expect from workflows built bottom-up. Usage of CWL requires some habit, not everything is well-explained in the tutorial. Some accents that I would stress so that new users do not need to second-guess:
CWL tends to be logic-less. Though it can receive an array of inputs, it doesn't have controllable loops by default. Control flows can be simulated, but one has to use the
ExpressionToolfor that, even for such "trivial" actions as getting arange(N)- and it is a separate calculation step.One should write any non-trivial commands using
ShellCommandRequirementstraight away.Internally, CWL represents data as
JSON.
The last property is very important, and that's a pity that the tutorial never clearly states
that. Because while piping data among POSIX commands would be complicated - as always -
when dealing with raw textual output, using CWL one can use JSON serialization and
speed up the pipeline design. Command-line transformations of JSON can be done with jq,
and database engines (even SQLite!) can wrap response data as JSON objects.
I use them everywhere in my pipeline, and every .cwl scenario is concise and clear.