
One of my favorite POSIX tools is a tiny NQ utility for creating
local task queues of shell commands. Its principle is described
in the top of a corresponding YC thread: wrap a log file of the process
in as many shared flock(2) -s as needed to be run before it in a queue.
When all locks released - execute. The log files' name template is
,TIMESTAMP.PID - quite a distinct scheme. And this file gets +x
bit during execution, so a state of "running" or "not running" for
a certain process is always visible.
It's a neat little tool, and I've already built a habit of using it
for persisting unix processes and small local task queues, instead of
e.g. nohup or pueue (sometimes my muscle memory invokes tmux but
I'm dropping that too). An extra benefit of minimalism is that this
tiny program compiles everywhere and works on remote clusters with
very limited available tooling and user permissions.
Recently I was pointed to another project that may become if not a complete
replacement but a main alternative to nq in my toolbox. The name's
HyperQueue, or hq for short, and it is a queue manager written in rust.
The architecture is server-based, each hq server instance orchestrates
a number of "workers" to whom shell commands can be submitted as "tasks".
The point is that hq is resource- and MPI scheduler-aware:
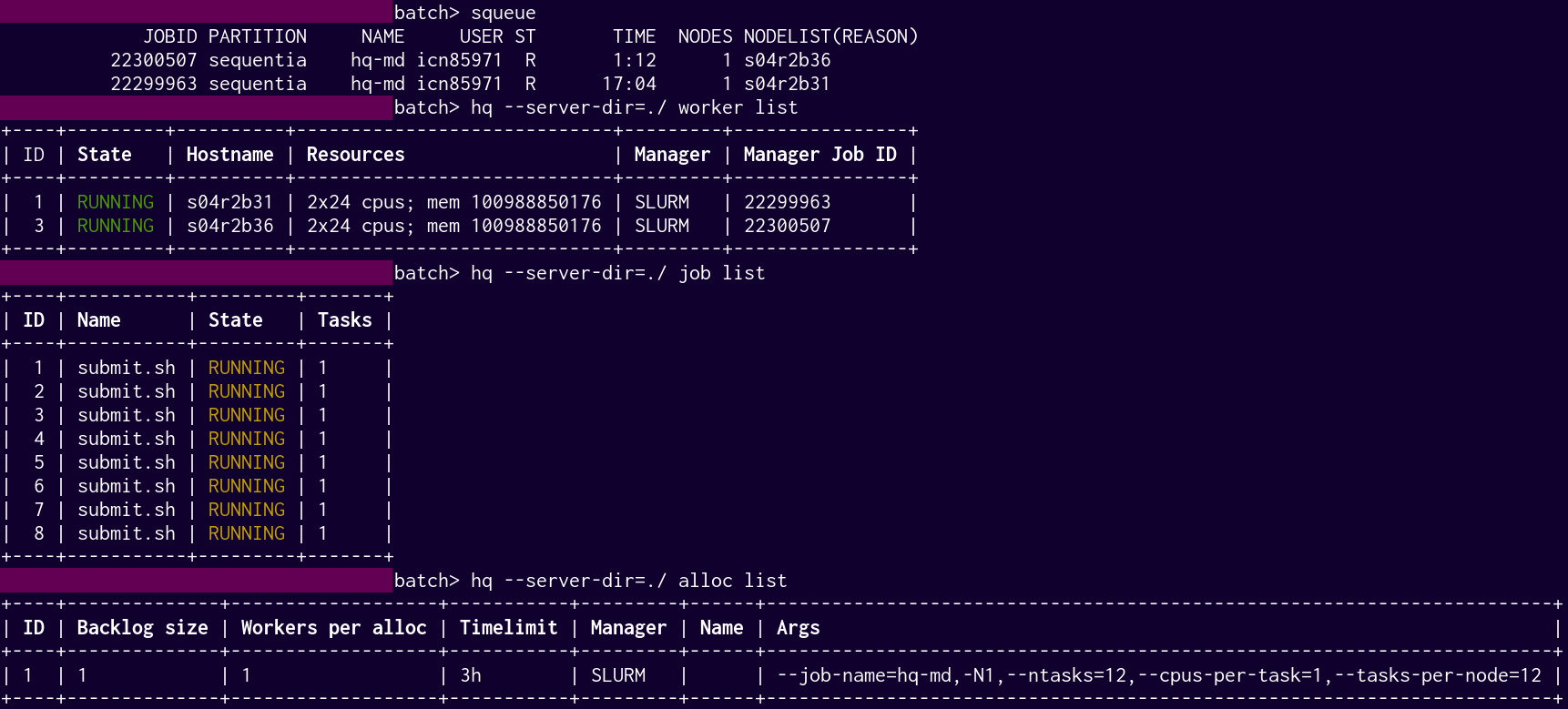
What is demonstrated in the screenshot above (top to bottom):
2
SLURMsubmissions, on 1 node each, corresponding with2
HQworkers, each orchestrating4
SIESTAMolecular Dynamics jobs submitted to HyperQueue - each parallelized over 12 cores (8 jobs in total)
Those 8 submissions were assigned workers dynamically, using HyperQueue dynamic allocation feature. Right after the start of the server, I created the allocation providing SLURM arguments that will be common to all jobs submitted to that particular HQ server. Those are listed in the bottom-right; I did not specify any SLURM-related directives in the submission scripts.
After that initialization, the HQ server itself creates workers in a number necessary to process the subsequent submissions (dynamically allocates them). When using SLURM that means "allocates enough nodes" in order to process the jobs submitted.
Currently, for dynamic allocation, hq creates one worker for each node. If many nodes are required for a job it should be submitted manually; see this issue. Hopefully that will be fixed soon.
In my example, 2 nodes are enough for 8 long tasks occupying 12 cores each, so eventually 2 nodes were allocated.
It was funny to notice that the queue separation is done similarly in
nq and hq: the distinction is based on a directory containing log
files. For HyperQueue setting the logging directory (and for each different
one, spawning an extra server instance) is done with the --server-dir
option.
To sum up, NQ is very handy for elementary job queues, and HyperQueue
looks very promising (and also easy to use) for heavy task workflows.
In my setup both these utilities live and even interplay: in order to
persist a HyperQueue server I actually spawn it with NQ:
nq hq --server-dir=./ server start
UPD [2022-05-02] As the dynamic allocator's behavior is not completely
clear to me yet (in particular, what's the policy of spawning and disconnection
of the workers), at the moment I use the manual worker submission to SLURM.
Workers occupy whole nodes when launched with mpirun in SBATCH scripts,
and job resource management with --cpus flag works as expected.
This way the ongoing job submissions effectively form a queue dispatched on the
allocated nodes as their resources are available. Keep in mind to submit
them with MPI.